The Producer-Consumer Model Explained
The producer-consumer model is a classic concept in computer science and is widely applied across various scenarios. This article introduces the producer-consumer model and explains how it works in both theory and practice.
What Is the Producer-Consumer Model?
To understand the producer-consumer model, let’s start with the literal meaning of “producer” and “consumer.” A producer is an entity that generates something—for instance, a factory producing goods. A consumer, on the other hand, is someone or something that uses what the producer has created—like a customer buying goods.
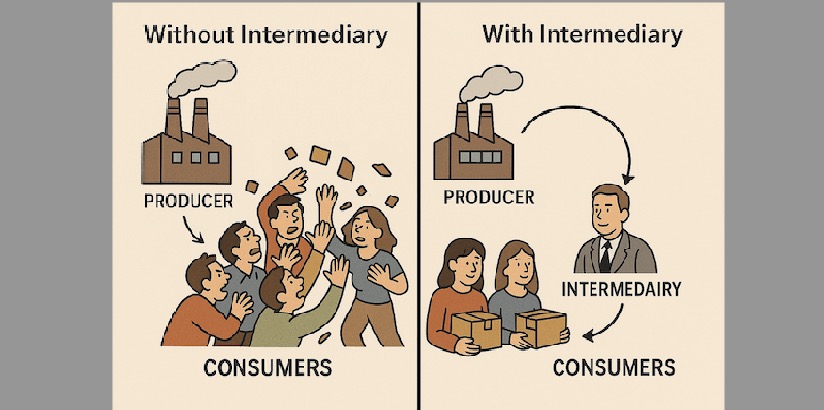
Imagine a factory producing products and consumers coming directly to the factory to purchase them. In this setup, the factory has to manage both the production of goods and the flow of consumers, which can quickly become chaotic. The responsibilities are unclear, and the management overhead increases significantly.
Now imagine a smarter approach: the factory delegates sales to distributors. The factory sends goods to the distributors, who then sell them to consumers. This is essentially the producer-consumer model:
The producer puts produced items into a buffer or queue, and the consumer retrieves items from there.
In this way, the producer can focus solely on production without worrying about how or when the consumer retrieves the items. The buffer decouples the producer and consumer, allowing each side to operate independently and more efficiently.
![[producer-consumer.png]]
Basic Implementation
In the previous section, we explained the concept of the producer-consumer model. Now let’s implement a basic version in code. In this example, the producer generates data, the consumer consumes it, and a simple array is used to simulate the buffer:
const BUFFER_SIZE: usize = 5;
fn main() {
let mut buffer = [-1; BUFFER_SIZE]; // simulated buffer
let mut write_pos = 0;
let mut read_pos = 0;
let mut count = 0;
let data_to_produce = [10, 20, 30, 40, 50, 60, 70]; // mock production data
let mut produced = 0;
let mut consumed = 0;
while produced < BUFFER_SIZE {
buffer[write_pos] = data_to_produce[produced];
produced += 1;
write_pos = (write_pos + 1) % BUFFER_SIZE;
count += 1;
println!("Produced: {}", data_to_produce[produced - 1]);
}
while count > 0 {
let item = buffer[read_pos];
println!("Consumed: {}", item);
read_pos = (read_pos + 1) % BUFFER_SIZE;
consumed += 1;
count -= 1;
}
}In this basic example, the producer fills the buffer with data, and the consumer then retrieves and processes it. While this version works, it has several limitations, which we will address in the next section.
Advanced Version
Let’s examine the shortcomings of the previous implementation:
- The producer and consumer operate in the same thread, so they can’t work simultaneously.
- The buffer has a fixed size (an array).
- Only a single consumer is supported.
While these are the main issues we’ll address for now, others remain—such as whether the buffer should be persistent, or whether it should support fault tolerance and rollback.
We can solve the concurrency and multiple-consumer issues by using multithreading. Instead of a fixed-size array, we can use a list (or VecDeque in Rust) to simulate an unlimited buffer. Here’s an improved version:
use std::sync::{Arc, Mutex, Condvar};
use std::collections::VecDeque;
use std::thread;
use std::time::Duration;
const BUFFER_SIZE: usize = 5;
struct SharedBuffer {
buffer: VecDeque<i32>,
max_size: usize,
}
fn main() {
let shared = Arc::new((
Mutex::new(SharedBuffer {
buffer: VecDeque::new(),
max_size: BUFFER_SIZE,
}),
Condvar::new(),
Condvar::new(),
));
let producer_shared = Arc::clone(&shared);
let consumer_shared = Arc::clone(&shared);
let producer = thread::spawn(move || {
for i in 0..10 {
let (lock, not_full, not_empty) = &*producer_shared;
let mut shared = lock.lock().unwrap();
while shared.buffer.len() == shared.max_size {
shared = not_full.wait(shared).unwrap();
}
println!("Produced: {}", i);
shared.buffer.push_back(i);
not_empty.notify_one();
thread::sleep(Duration::from_millis(200));
}
});
let consumer = thread::spawn(move || {
for _ in 0..10 {
let (lock, not_full, not_empty) = &*consumer_shared;
let mut shared = lock.lock().unwrap();
while shared.buffer.is_empty() {
shared = not_empty.wait(shared).unwrap();
}
if let Some(data) = shared.buffer.pop_front() {
println!("Consumed: {}", data);
}
not_full.notify_one();
thread::sleep(Duration::from_millis(300));
}
});
producer.join().unwrap();
consumer.join().unwrap();
}Here, both the producer and consumer run in separate threads and access a shared buffer. Synchronization is handled using Mutex and Condvar to prevent race conditions and signal availability.
Although this example uses a list for the buffer, we’ve still limited its size to reduce the risk of memory leaks.
Alternatively, a ring buffer can be used for more efficient memory usage and performance.
Performance-Oriented Version
The multithreaded in-memory implementation is a significant improvement, but it still falls short in high-concurrency, large-scale, and microservice environments. For further optimization, we can explore:
- Distributed Message Queues
Transforming the in-memory buffer into a distributed one allows cross-process and cross-instance communication. - Multiple Producers and Consumers
Scaling both the production and consumption ends improves throughput and parallelism. - Persistence and Fault Tolerance
Storing buffer data persistently ensures that data isn’t lost during crashes, improving reliability.
Popular tools that embody these advanced producer-consumer patterns include Kafka, Pulsar, Redpanda, and RabbitMQ.
Conclusion
In this article, we introduced the producer-consumer model and implemented a basic single-threaded version. We then identified its limitations, built a multithreaded memory-based version, and finally discussed advanced enhancements for real-world, high-performance systems.
In future articles, we will continue exploring topics related to producers and consumers in greater depth.